Harry WangA Practical Guide to Quasi-Experimental Methods (PSM and DID)A quasi-experiment is an empirical interventional study used to estimate the causal impact of an intervention on target population without…Jun 1, 2022Jun 1, 2022
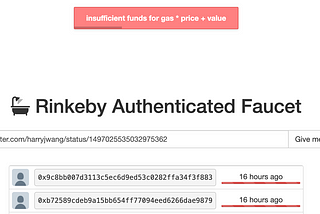
Harry WangGet Test Ethers using SeleniumI need some test ethers for Rinkeby and found out that the faucet is not working (I also don’t like that you have to tweet to get the…Feb 24, 2022Feb 24, 2022
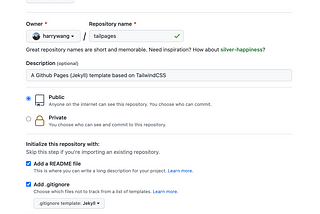
Harry WangDeveloping Tailpages: A Jekyll Template based on Tailwind CSSTailpages Developer TutorialJan 12, 2022Jan 12, 2022
Harry WangIntroducing Tailpages (Tailwind + Github Pages)Setup free-hosted beautiful website without codingJan 11, 2022Jan 11, 2022
Harry WangA Minimalist End-to-End Scrapy Tutorial (Part V)Systematic Web Scraping for BeginnersApr 13, 20201Apr 13, 20201
Harry WangHow to organize a self-contained Python projectI often use and study open-source code from the Internet and run into the following situation:Feb 5, 2020Feb 5, 2020
Harry WangHow to Host Static Markdown/Web pages using Github PagesGithub Pages allow you to host static markdown/web pages (HTML and JS) for free. You only need a few steps to have a website up and…Nov 18, 20191Nov 18, 20191
Harry WanginTowards Data ScienceA Minimalist End-to-End Scrapy Tutorial (Part IV)Systematic Web Scraping for BeginnersSep 12, 20197Sep 12, 20197
Harry WanginTowards Data ScienceA Minimalist End-to-End Scrapy Tutorial (Part III)Systematic Web Scraping for BeginnersSep 12, 20194Sep 12, 20194